


The software recognizes various acoustic signals including bird call, voice and impact sound using Two-dimensional GD. The software works on Microsoft Windows. First, you record the sounds into the WAV files using a data recorder.
On the first screen of the software, we previously register waveforms recorded in WAV files. As shown on the right of Figures 1 and 2, the software gives FIR digital filter processing to the waveform of the sound, and extracts the spectrum pattern (standard pattern) from the filtered waveform using the LPC (Linear Predictive Coefficient) spectrum analysis.
On the second screen of the software, we input a continuous recording waveform from WAV file. As shown on the left of Figures 1 and 2, the software gives FIR digital filter processing to the continuous recording waveform. Then, the software segments the waveform of the target sound from the continuous recording automatically, and extracts the spectrum pattern (input pattern) from the segmented waveform.
On the second screen, the software numerically evaluates the degree of likeness between the input pattern and the standard pattern using the similarity scale “Tow-dimensional GD”, and recognizes the input pattern.
As a concrete example, we describe respective processing of “registration of standard pattern”, “segmentation of target sound” and “recognition of input pattern” using a waveform of the bird vocalization in the following.
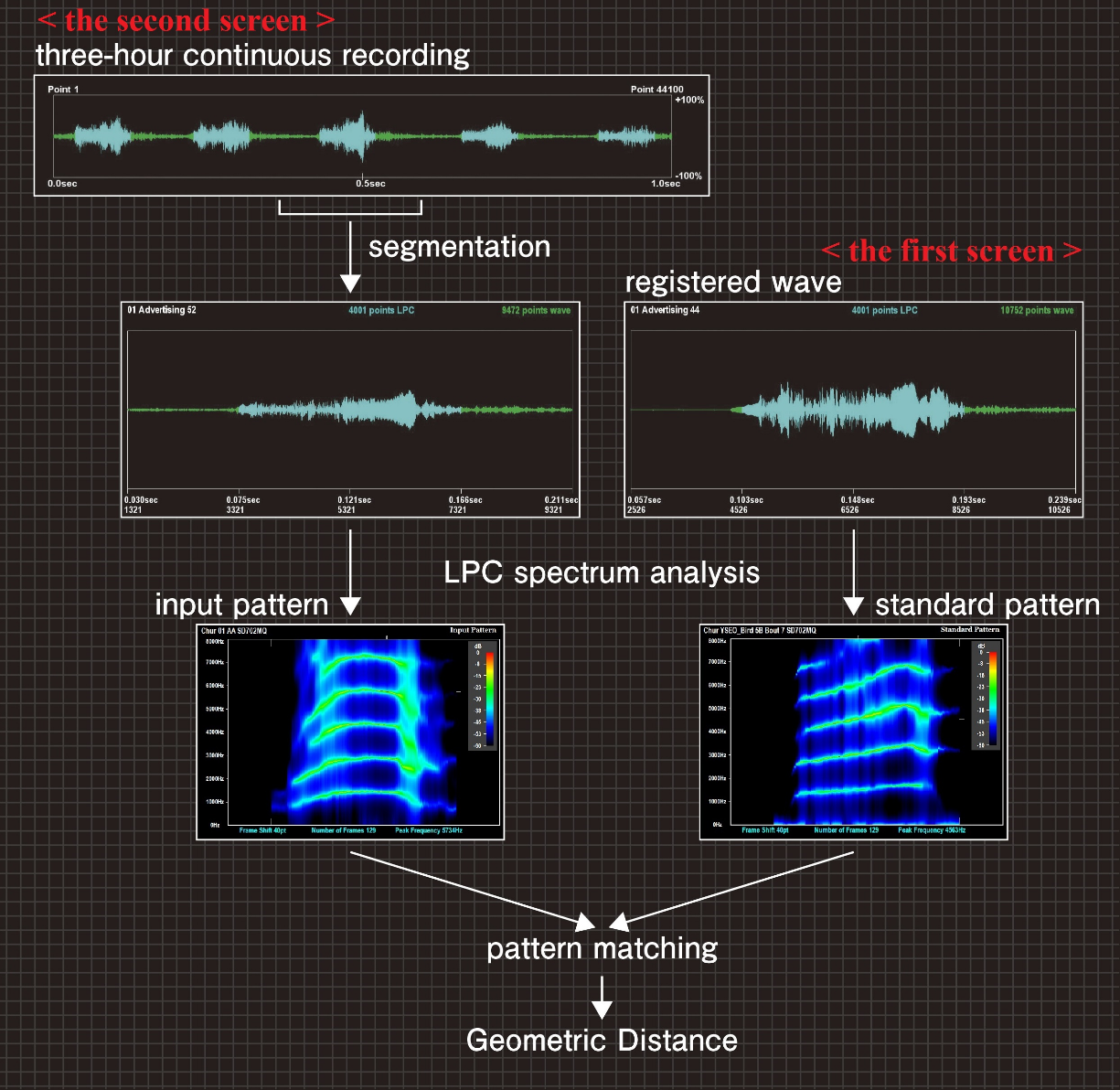
Figure 1. Processing procedure in recognition system

Figure 2. Processing procedure in recognition system
Processing Procedure
Registration of standard pattern:
On the first screen shown in Figure 3, we register a plural number of sound waveforms into each cluster (Clusters 2-14).
As shown on the right of Figures 1 and 2, the software gives FIR digital filter processing to the sound waveform, and extracts the spectrum pattern (standard pattern) from the filtered waveform using the LPC spectrum analysis.
On the first screen, the spectrum image of the standard pattern is displayed and the original sound or the filtered sound of the waveform is output from the loudspeaker.
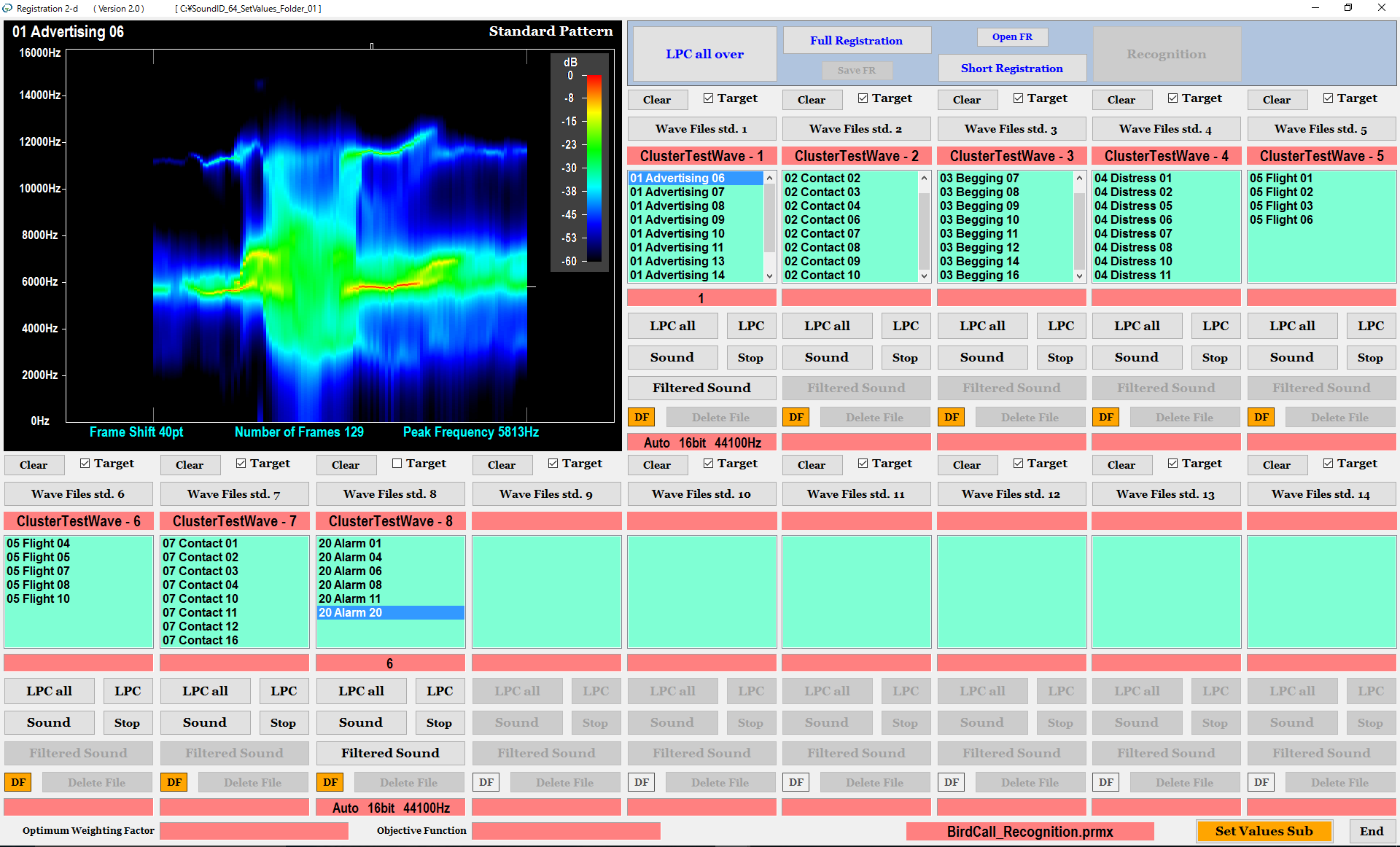
Figure 3. Registration of standard pattern (The first screen)
Segmentation of target sound:
Figure 4 shows the screen of the segmentation. As shown on the left of Figures 1 and 2, the software gives FIR digital filter processing to the continuous recording waveform. Then, the software segments the waveform of the target sound from the continuous recording automatically In order to reduce the processing overhead, the recognition software does not display the image shown in Figure 4. We can confirm the result of segmentation using the segmentation software prepared separately from the recognition software.
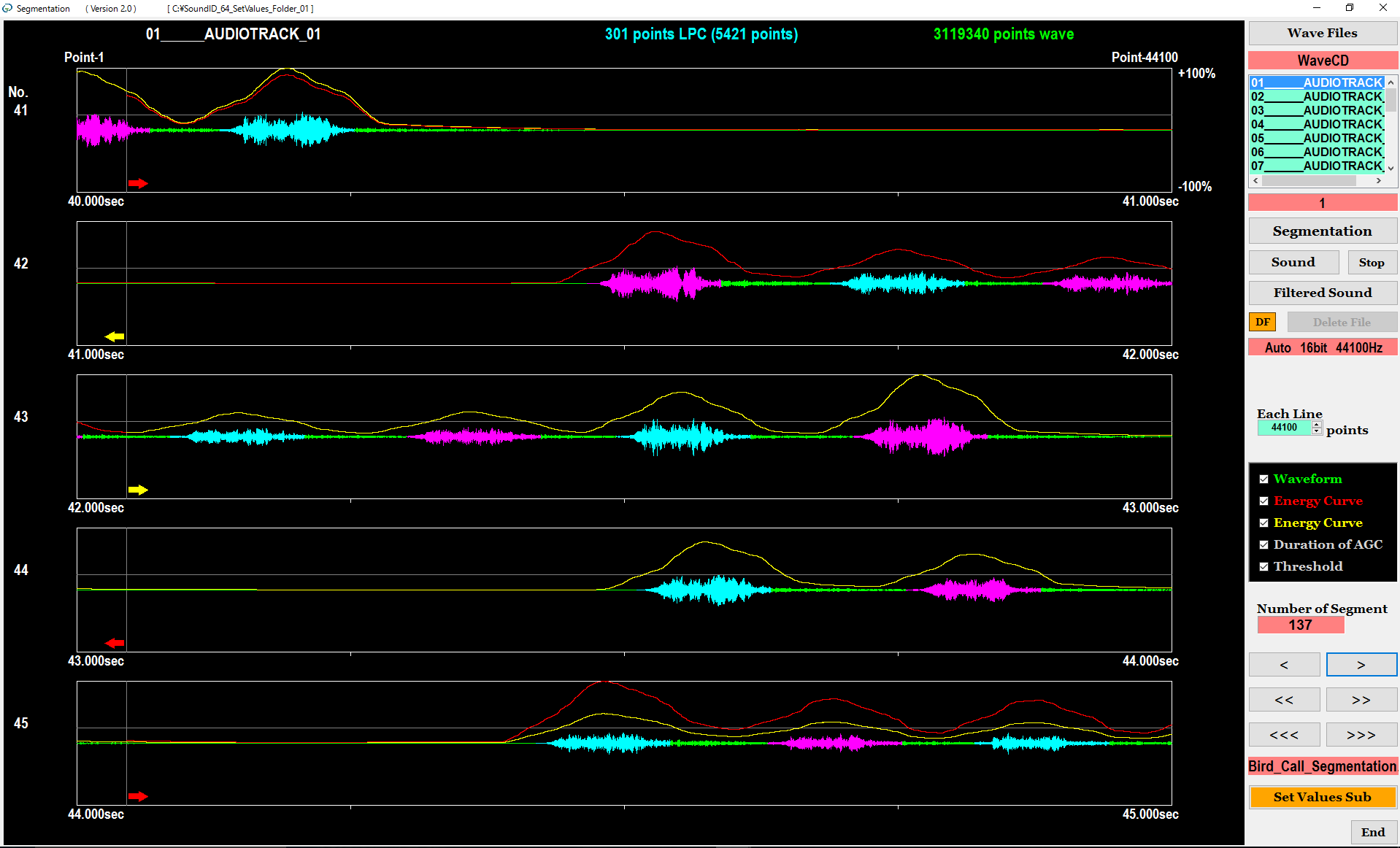
Figure 4. Segmentation of target sound
Recognition of input pattern:
On the second screen shown in Figure 5, the software extracts the spectrum pattern (input pattern) from the waveform segmented in the above segmentation, and displays the input pattern on the left of the screen.
Next, using Two-dimensional GD, the software compares the spectrum pattern (a single input pattern) of the input sound with each of the spectrum patterns (a plural number of standard patterns) registered on the first screen. Then, the software displays the standard pattern having the smallest distance from the input pattern on the right of the screen.
Furthermore, as a result of the recognition, the software displays the name of the standard pattern at the bottom of the screen. Also, the bar graph on the right shows the value of the smallest distance.
The software repeats the above recognition processing for a plural number of input patterns segmented in the segmentation processing, and recognizes all of the target sounds included in the continuous recording. As a result of the recognition, the software displays the time of the input pattern in the continuous recording, the name of the standard pattern having the smallest distance from the input pattern and the smallest distance value at the bottom of the screen.
On the second screen, if you click the recognition results at the bottom of the screen, then the software displays the spectrum images of the input and standard patterns and outputs the filtered sound of the input pattern form the loudspeaker.
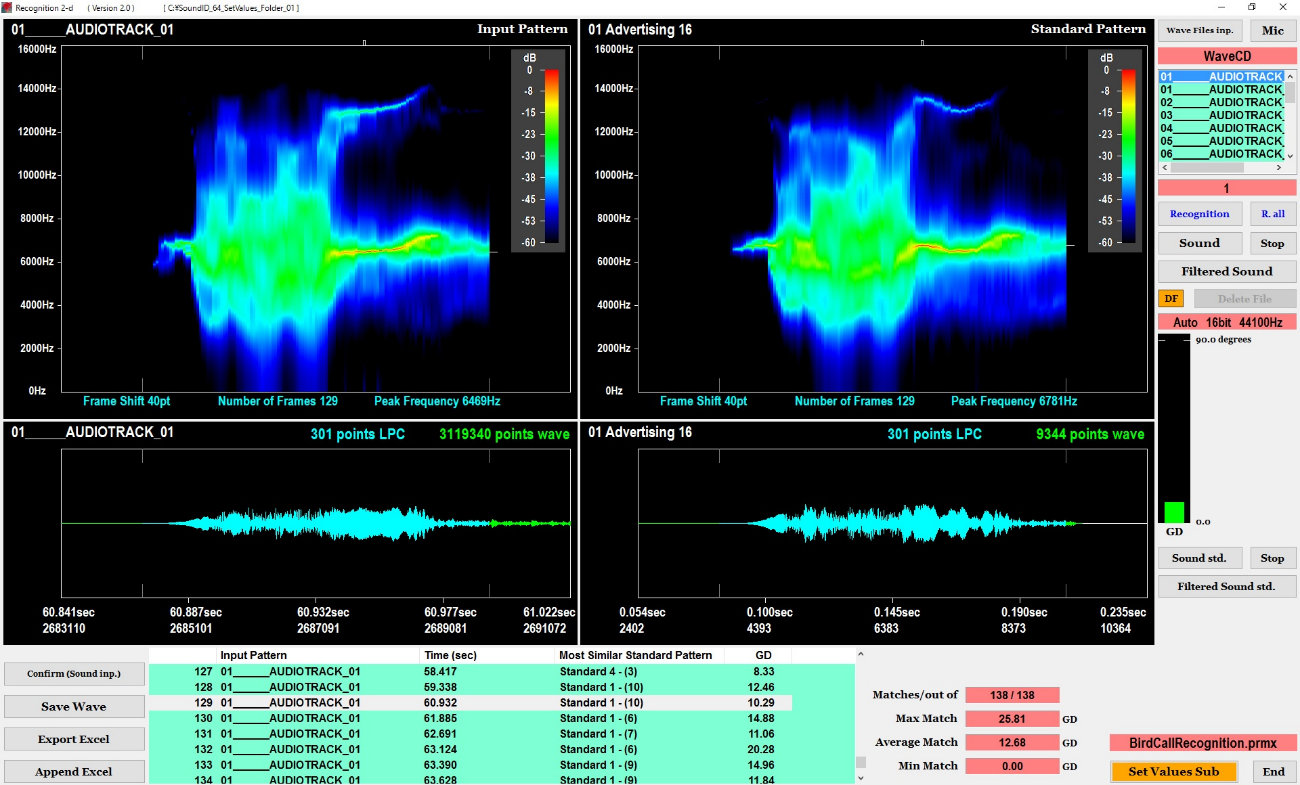
Figure 5. Recognition of input pattern (The second screen)
